Wohin gehen all die Kommentare, visualisiert
Herr Leu hat letzthin davon geschrieben, dass das Kommentar-Volumen auf seinem Blog in der letzten Zeit ziemlich abgenommen hat, während die Reaktionen auf die Beiträge in anderen Kanälen stattfinden.
Dies ist mir auch schon lange aufgefallen, ich konnte es aber nicht wirklich mit Zahlen belegen. Da Herr Leu auch grad noch eine handliche MySQL-Abfrage zur Abfrage der Zahlen mitlieferte, hab’ ich mir mit Sequel Pro die Zahlen aus meiner Blog-Datenbank geholt.
Für mich sieht das Resultat der obigen Abfrage so aus:
Year Count Average
2003 157 0.3057
2004 316 0.6108
2005 197 1.2589
2006 144 1.4375
2007 140 2.8143
2008 146 2.5685
2009 93 3.7419
2010 90 3.1333
2011 73 1.3973
2012 17 0.4706
Ein Peak im Jahr 2009 ist klar erkennbar, danach sinken die Kommentarzahlen absolut und im Durchschnitt. Da ich aber der visuelle Mensch bin, hab’ ich mir gedacht, dass sich diese Zahlen (genau wie bei Herr Leu übrigens) doch in eine schöne Grafik verpacken lassen sollten.
Deshalb hab’ meinen Lieblingseditor gestartet und untenstehendes Python-Skript geschrieben. Das Skript liest die Zahlen aus einem Text-File und stellt die durchschnittlichen Kommentare normiert als Plot über die Jahre dar. Das einlesen aus einem Text-File hab’ ich gemacht, damit sich nicht nur meine Zahlen, sondern auch diejenige visualisieren lassen, welche andere in den Kommentaren bei Herr Leu angegeben haben.
[python] #! /opt/local/bin/python
import optparse from pylab import *
Use Pythons Optionparser to define and read the options, and also #
give some help to the user #
parser = optparse.OptionParser() usage = "usage: %prog [options] arg" parser.add_option(’-n’, dest=‘Name’, metavar=‘Fridolin’) (options, args) = parser.parse_args()
show the help if no parameters are given #
if options.Name==None: parser.print_help() print ’’ print ‘Example:’ print ‘The command reads the comment from "comments_sepp.txt"’ print ‘and plots them nicely.’ print ’’ print ‘comments.py -n sepp’ print ’' sys.exit(1) print ''
Data = genfromtxt(‘comments_’ + str(options.Name) + ‘.txt’,skip_header=True)
MaxAverage = 0 for line in Data[:,2]: MaxAverage = max(MaxAverage,line)
ax = plt.subplot(111) ax.plot(Data[:,0],Data[:,2]/MaxAverage) ax.axis([2003,2012,0,1]) ax.xaxis.set_major_formatter(FormatStrFormatter(’%d’)) title(‘Normalized comments for ’ + str(options.Name)) savefig(str(options.Name) + ‘.png’)
[/python]
Als ich das kleine Skript mit den angegebenen Zahlen laufen liess, entstehen untenstehende Plots. Schön ist zu sehen, dass der Kommentarhöhepunkt bei allen (Markus, Robert, Roger, Manuel [1] und mir) teilweise deutlich überschritten scheint. Ich persönlich bewege mich nicht (mehr) auf Twitter und Facebook, erhalte also auch von dort keine Rückmeldungen.
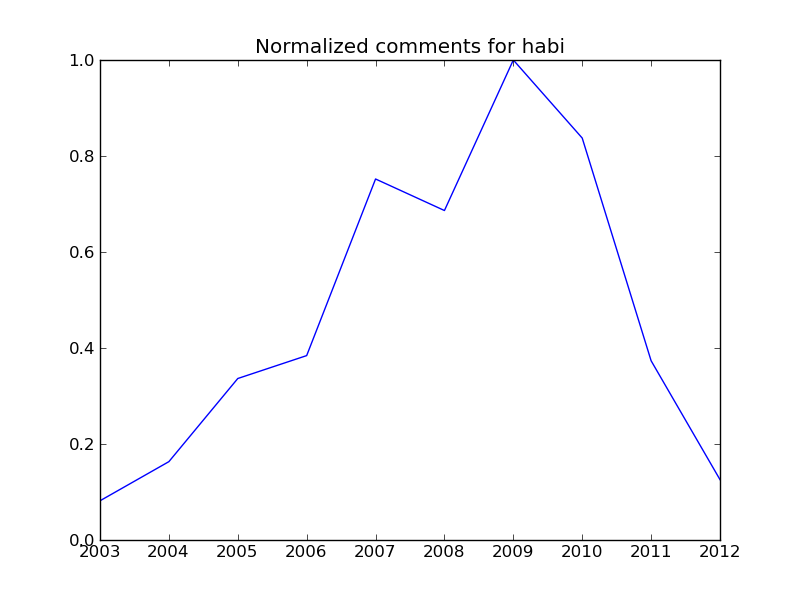

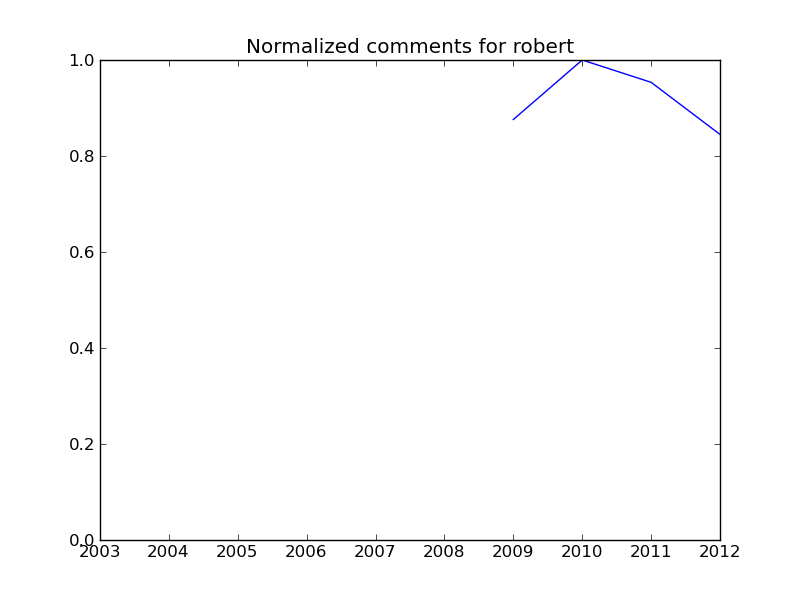
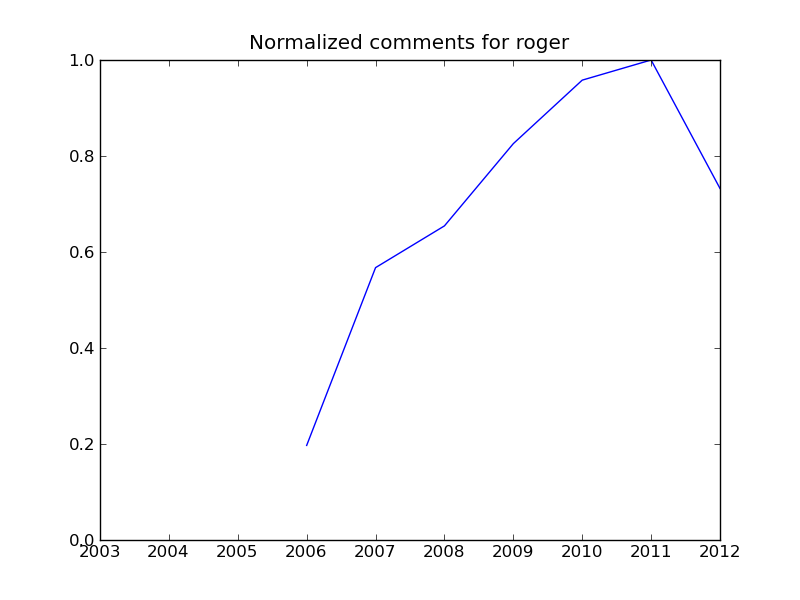
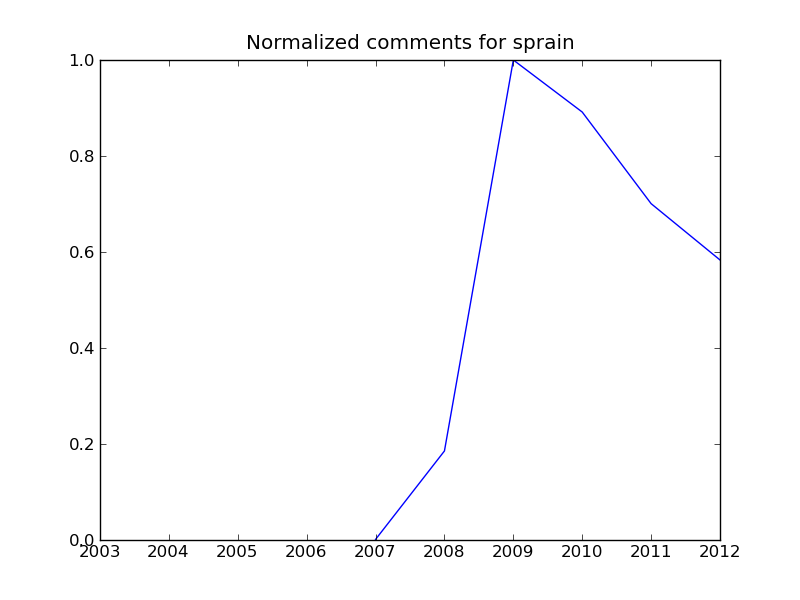
Um’s genau wie Herr Leu zu sagen: Auch wenn ich das ganze als Python-Fingerübung benutzt habe, wünsche ich mir mehr Kommentare hier, auch - oder gerade wenn - ein Beitrag nicht gefällt, oder du eine andere Meinung hast.
[1]: der mich übrigens mit dem “wenn auch auf tieferem Niveau” in seinem Kommentar drüben bei Herr Leu dazu gebracht hat, die durchschnittlichen Kommentare zu normalisieren.